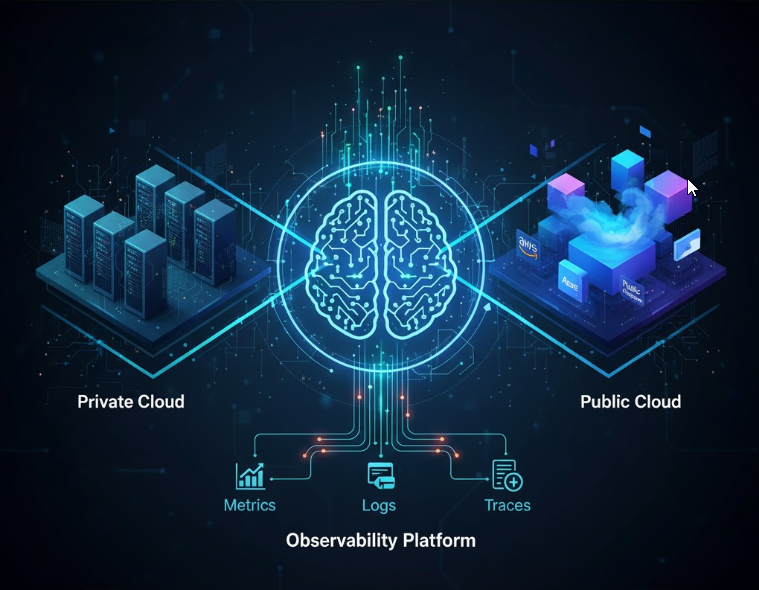
ในภูมิทัศน์ของเทคโนโลยีสารสนเทศยุคปัจจุบัน องค์กรต่างๆ ได้ทรานส์ฟอร์มไปสู่โครงสร้างแบบ Hybrid Cloud และ Multi-Cloud เพื่อเพิ่มความคล่องตัวทางธุรกิจและลดค่าใช้จ่าย อย่างไรก็ตาม การบริหารจัดการเครือข่ายภายใต้สถาปัตยกรรมที่ซับซ้อนนี้ ก่อให้เกิดความท้าทายใหม่ๆ การพึ่งพาเครื่องมือ Network Monitoring แบบดั้งเดิม (เช่น การเช็ก Ping หรือ SNMP) ซึ่งเน้นที่การตรวจสอบสถานะ Up/Down ของอุปกรณ์เครือข่ายนั้นไม่เพียงพออีกต่อไป ไม่สามารถให้ข้อมูลเชิงลึกที่จำเป็นต่อการแก้ไขปัญหาประสิทธิภาพแอปพลิเคชันที่รวดเร็วได้
ด้วยเหตุนี้ แนวคิด “Network Observability” จึงได้กลายเป็นแนวทางที่สำคัญยิ่งขึ้นในการทำความเข้าใจพฤติกรรมของเครือข่ายอย่างครอบคลุม โดยเปลี่ยนจากการ “เฝ้าระวัง” (Monitoring) ไปสู่การ “ทำความเข้าใจเชิงลึก” (Deep Understanding) ผ่านข้อมูลที่สมบูรณ์แบบเพื่อ Optimize Hybrid Cloud ให้มีประสิทธิภาพสูงสุด บทความนี้จะเจาะลึกถึงหลักการของ Network Observability และวิธีนำมาใช้เพื่อเพิ่มประสิทธิภาพการดำเนินงานของเครือข่ายในสภาพแวดล้อม Hybrid Cloud
1. Network Observability คืออะไร: Beyond Traditional Monitoring
Network Observability คือความสามารถในการทำความเข้าใจสถานะภายในของระบบเครือข่าย โดยอาศัยการรวบรวมและวิเคราะห์ข้อมูล Telemetry จากทุกองค์ประกอบของเครือข่ายอย่างต่อเนื่อง เพื่อตอบคำถามที่ซับซ้อนเกี่ยวกับประสิทธิภาพและพฤติกรรมของเครือข่ายอย่างรวดเร็วและแม่นยำ
ความแตกต่างระหว่าง Monitoring และ Observability สามารถสรุปได้ดังนี้:
- Traditional Monitoring: มุ่งเน้นการเฝ้าดู “สิ่งที่เรารู้ว่าต้องดู” (Known-Knowns) เช่น การใช้ Bandwidth, CPU Load, สถานะ Up/Down ของอุปกรณ์ เป็นการตั้ง Dashboard และ Alert ตามเกณฑ์ที่กำหนดไว้ล่วงหน้า
- Network Observability: มุ่งเน้นความสามารถในการสำรวจและทำความเข้าใจ “สิ่งที่เราไม่รู้มาก่อน” (Unknown-Unknowns) เช่น เมื่อผู้ใช้รายงานว่า “แอปพลิเคชันช้า” Observability ช่วยให้วิศวกรสามารถเจาะลึก ค้นหาสาเหตุที่ไม่เคยคาดคิด และระบุปัญหาได้อย่างรวดเร็ว
2. องค์ประกอบสำคัญของ Network Observability (The 3 Pillars)
Network Observability อาศัยข้อมูล Telemetry 3 ประเภทหลัก ซึ่งเป็นรากฐานของการวิเคราะห์เชิงลึก:
- Metrics (เมตริก): ข้อมูลเชิงปริมาณที่เก็บรวบรวมอย่างต่อเนื่องในช่วงเวลาหนึ่ง เช่น
- Latency (ความหน่วง): เวลาที่ข้อมูลใช้ในการเดินทาง
- Packet Loss (ข้อมูลสูญหาย): เปอร์เซ็นต์ของแพ็กเก็ตข้อมูลที่ไม่ถึงปลายทาง
- Throughput (ปริมาณงาน): อัตราการรับส่งข้อมูลสูงสุด
- CPU/Memory Utilization: การใช้งานทรัพยากรของอุปกรณ์เครือข่าย ข้อมูลเหล่านี้ช่วยให้เห็นแนวโน้มและประสิทธิภาพของเครือข่ายในภาพรวมแบบเรียลไทม์
- Logs (ล็อก): บันทึกเหตุการณ์ที่เกิดขึ้นในอดีต ซึ่งมาจากอุปกรณ์เครือข่ายต่างๆ เช่น Syslogs, Firewall Logs, DNS Logs
- ข้อมูลใน Logs: จะบอกถึงเหตุการณ์เฉพาะเจาะจงที่เกิดขึ้น (Who, What, When, Where) เช่น การ Login ล้มเหลว, การเปลี่ยนแปลงการตั้งค่า, การบล็อกการเชื่อมต่อโดย Firewall
- ประโยชน์: ช่วยในการสืบสวนหาที่มาของปัญหา และเป็นหลักฐานสำหรับการตรวจสอบความปลอดภัย
- Traces (การติดตาม): เป็นข้อมูลที่แสดงถึงเส้นทางการเดินทางของ “Request” หรือ “Transaction” ของแอปพลิเคชันแบบ End-to-End
- การทำงาน: ติดตามทุกขั้นตอนของ Request ตั้งแต่ผู้ใช้เริ่มดำเนินการ (เช่น คลิกปุ่ม) ผ่าน Microservices, API Gateways, Database, และส่วนต่างๆ ของเครือข่ายและ Cloud
- ความสำคัญ: ช่วยให้เห็นภาพรวมของประสิทธิภาพแอปพลิเคชันอย่างแท้จริง และระบุ “คอขวด” (Bottleneck) ที่อาจเกิดในส่วนใดส่วนหนึ่งของระบบได้อย่างแม่นยำ ไม่ว่าจะเป็นในเครือข่ายภายใน (Private Cloud) หรือบริการ Cloud สาธารณะ (Public Cloud)
3. การใช้ Network Observability เพื่อ Optimize Hybrid Cloud
การนำหลักการ Network Observability มาประยุกต์ใช้ในสภาพแวดล้อม Hybrid Cloud ก่อให้เกิดประโยชน์อย่างมหาศาล:
- การระบุสาเหตุที่แท้จริงของปัญหา (Root Cause Analysis – RCA) อย่างรวดเร็ว:
- ด้วยการรวบรวม Metrics, Logs, และ Traces จากทั้ง Private Cloud และ Public Cloud เข้ามาในแพลตฟอร์มเดียว วิศวกรสามารถเชื่อมโยงข้อมูลและระบุได้อย่างแม่นยำว่าปัญหาประสิทธิภาพของแอปพลิเคชันเกิดจากส่วนใด เช่น Network Congestion, Latency ในการเชื่อมต่อ Public Cloud, หรือปัญหาประสิทธิภาพของ Workload ใน Private Cloud
- ลดเวลา Mean Time to Resolution (MTTR) ได้อย่างมีนัยสำคัญ
- การเพิ่มประสิทธิภาพการทำงานของแอปพลิเคชัน (Application Performance Optimization):
- Observability ช่วยให้เข้าใจว่าแอปพลิเคชันมีการใช้งานเครือข่ายอย่างไรในแต่ละสภาพแวดล้อม (On-premise vs. Cloud)
- สามารถระบุ Traffic Pattern ที่ผิดปกติ หรือ Optimize Routing Path เพื่อให้แอปพลิเคชันที่มีความสำคัญสูง (เช่น SAP, ERP) มีประสิทธิภาพสูงสุดบน Hybrid Cloud
- การปรับปรุงประสบการณ์ผู้ใช้ (Enhanced User Experience):
- จากข้อมูล Traces ที่ติดตาม Request แบบ End-to-End ทำให้องค์กรสามารถวัดผล “ประสบการณ์จริง” ของผู้ใช้ แทนที่จะดูแค่สถานะ Up/Down ของอุปกรณ์
- สามารถแก้ไขปัญหาเชิงรุกได้ก่อนที่ผู้ใช้จะได้รับผลกระทบ ทำให้เกิดความพึงพอใจและสร้างความน่าเชื่อถือให้กับบริการ
- การบริหารจัดการต้นทุน Cloud อย่างมีประสิทธิภาพ:
- ด้วยการมองเห็นภาพรวมของ Traffic Flow และ Utilization ในส่วนของ Public Cloud องค์กรสามารถปรับขนาดทรัพยากร (Scale Up/Down) หรือปรับการตั้งค่า Network Gateway เพื่อลดค่าใช้จ่ายที่ไม่จำเป็น
4. สรุป (Conclusion)
Network Observability คือกุญแจสำคัญในการปลดล็อกศักยภาพสูงสุดของโครงสร้างพื้นฐานแบบ Hybrid Cloud และ Multi-Cloud มันไม่ใช่เพียงแค่เครื่องมือเฝ้าระวัง แต่เป็นแพลตฟอร์มที่ให้ข้อมูลเชิงลึกอันทรงพลัง ช่วยให้ทีมไอทีสามารถเข้าใจ, วิเคราะห์, และแก้ไขปัญหาเครือข่ายได้อย่างรวดเร็วและแม่นยำ
การลงทุนใน Network Observability Platform ที่ดี จะช่วยให้องค์กรสามารถ Optimize Hybrid Cloud ได้อย่างยั่งยืน, เพิ่มประสิทธิภาพการทำงานของแอปพลิเคชัน, ยกระดับประสบการณ์ผู้ใช้, และเตรียมพร้อมรับมือกับความท้าทายด้านเครือข่ายที่ซับซ้อนในอนาคตได้อย่างมั่นใจ
อ่านบทความเพิ่มเติมที่ : https://www.itbtthai.com/category/itbt-activities/
อ่านบทความต่อได้ที่ : https://www.networkcomputing.com/network-observability/is-network-observability-different-from-visibility-and-monitoring-
เรียบเรียงโดย บรรพต ทองวิจิตร
